Searching for the Magic KM Bullet: How technological trends will impact the
development of Knowledge Management
![]()
By Vince Cavasin
MIS 381n7
Information and Knowledge Management
Dr. Tom Davenport
May 11, 1998
Contents
Executive summary
*Introduction
*Defining the magic bullet
*Let’s get real
*The rational bullet
*Knowledge Management process framework
*Knowledge Acquisition
*Fitting it all together
*Endnotes
*Bibliography
*Exhibit 1: Representative current KM
process
Exhibit 2: KM process revised to include
"rational bullet" automation
Exhibit 3: Proposed integrated knowledge base
model for KM applications
I assert that the field of Knowledge Management (KM) is in its infancy due to the enormous potential of developing technologies that it can leverage. This paper examines how long- and short-term technological progress will impact KM.
In the long term, when the promise of Artificial Intelligence research culminates in machines that can think and interact indistinguishably from human beings, we will have the ultimate "magic KM bullet": machines that combine the computational abilities and memory capacity of computers with the software-emulated, conversational knowledge transfer abilities of human experts.
The shorter term is perhaps more interesting, since it is somewhat more tangible and less fantastic. In this part of the paper, I attempt to relate the expected fruits of current AI research projects to KM development over the next 10 or so years.
The emerging technologies examined are divided into two categories: initial knowledge acquisition and sustained learning. Initial acquisition technologies include natural language processing, neural networks (vs. symbolic representation schemes), and software capable of observing and summarizing work. Sustained learning technologies consist of models that decide when to change beliefs based on contradictory data.
Along with these technologies, I propose a new Knowledge Management knowledge base model to extend the knowledge available to KM practitioners to include general knowledge as well as the traditionally included reusable "knowledge objects."
Where is my magic KM bullet?
I began my study of Knowledge Management expecting to find a real-world offshoot of AI, poised for explosive growth as an industry itself, but also poised to add millions to KM-savvy companys' bottom lines by giving them an enormous competitive advantage. More interestingly, perhaps, I expected these advantages to appear via canned KM software solutions that companies could simply install and forget.
Having learned the state-of-the-KM-art, I now accept that this magic bullet is a long way off, but I fully expect it to arrive. I still believe that KM does have enormous potential for both providers and users; in fact, I’d say it’s currently in its infancy. It is KM’s youth, along with the current state of the technology that it relies upon, that promises that rather than being just another IT fad, KM may potentially become a fundamental and necessary information-related business function. I draw an analogy between KM’s current state and IM’s state 40 years ago: visionary companies are embracing it, even though the current technology is clunky and labor-intensive; debate over the value and responsibilities of the CKO rages now as it raged then for the CIO; and no one can accurately predict where maturing KM practices and technologies will end up. Since I take some pleasure in predicting the unpredictable, this paper focuses on how the magic KM bullet will evolve, given the current state of the art and industry requirements.
To set an absolute (and absolutely absurd) upper bound on what KM can accomplish, I’ll say that it would involve instantaneous, effortless access to the exact knowledge that an employee needs to maximize the return on an intellectual investment she is making.
Today, the closest thing we have to a KM magic bullet is interactive contact with a human expert. This is evident not only from common sense (would you rather gain knowledge by querying a database or talking directly with an expert?), but also from the proliferation of devices like knowledge maps in companies such as Hoffmann-LaRoche, Hughes Communication, Microsoft and others (Davenport, 1998).
Thinking in this paradigm, it’s tempting to envision a Star Trek-like future computer that will impart knowledge via conversation. In fact, such a machine is virtually inevitable: strong AI advocates point out that assuming the historic rate [1] of hardware technology advancement continues, we will have desktop machines with computational capability and memory capacity equal to the human brain—roughly 100,000 TeraFLOPS [2] and 1010 Megabytes, respectively—by around 2040 (Tipler, 1994). It will take a few decades for both software and cognitive science to catch up, but there is little doubt that machines will be capable of thinking and interacting indistinguishably from humans by late in the 21st century [3]. Unconstrained by memory capacity, such machines will store any and all information potentially required by their users; unconstrained by processing power, their software will intelligently and interactively work with a user—perhaps more efficiently than a human expert currently can—to determine exactly what information the user needs, and how to transform it into the knowledge that will best help him do his job.
My hypothetical future machine is rather boring; I can’t describe it in detail, because the technology to create it (never mind the sociology to deal with it) doesn’t exist yet. Instead, I’d like to look at the more tangible topic of current AI research that is likely to have nearer-term KM applications. Undoubtedly, such research will contribute to the technical foundations upon which my magic bullet will be built; either through direct software evolution, or, more likely, due to the lessons it provides about the act of thinking.
If the magic KM bullet is nearly 100 years off, how can we expect the evolution toward it to progress over a more realistic period, say the next 10 years? The recent progress most relevant to my magic bullet involves the area of Knowledge Acquisition (KA). The human-labor-intensive (and therefore costly) nature of current KA methods is, in my opinion, the biggest obstacle to the widespread adoption of KM.
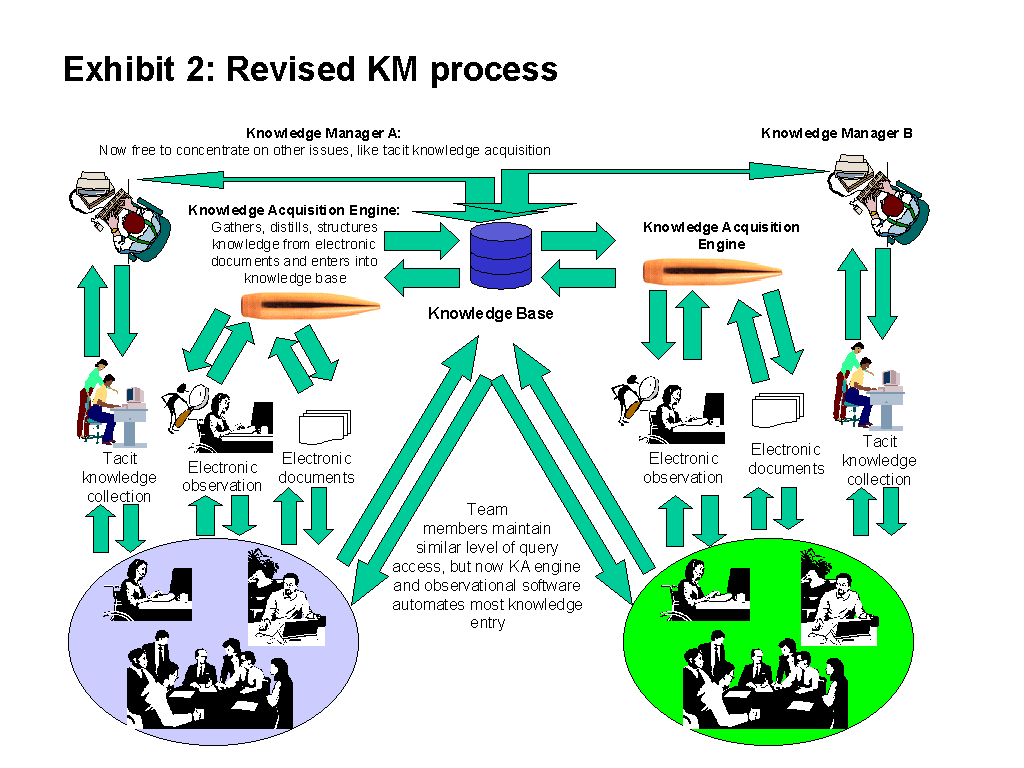
Automating KA will provide the huge pragmatic benefit of eliminating the costly process of transferring knowledge from the knower’s head into a knowledge base. Consulting companies that use KM find that while clients are happy to pay dedicated Knowledge Managers who leverage the firm’s knowledge base for client benefit, they are reluctant to pay those consultants to input knowledge gained on the client’s project. Fully automating KA will not only free such KM consultants from having to perform the mechanical input process, thus freeing them to do more productive work, but it will eliminate the cost of collecting knowledge from an engagement, rendering irrelevant the client’s reluctance to pay for it. Of course, full automation of KA lies more in the territory of the magic bullet than the rational one, but I believe much technology exists that can be leveraged to automate the acquisition of non-tacit knowledge.
Knowledge Management process framework
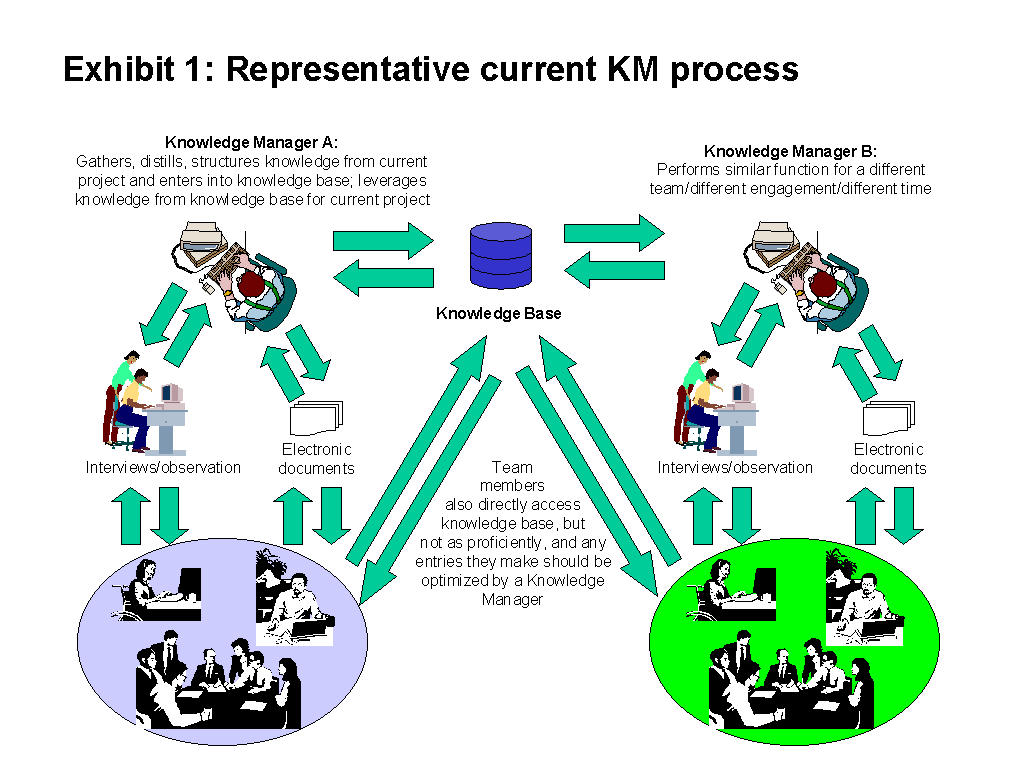
Exhibit 1 shows my view of a representative KM process: a consulting engagement. Exhibit 2 shows a revised process which assumes full implementation of the emerging technologies that I believe have great potential to advance the state of the art in Knowledge Acquisition, and which are discussed below.
In the context of KM, KA is currently done predominantly by humans. Positions such as Ernst & Young’s Knowledge Steward exist primarily to collect knowledge from engagement teams and figure out how to best package it in the knowledge base so as to facilitate reuse. Human Knowledge acquirers work both with documents and through observation of and interviews with knowledge sources; their automated counterparts will, at least for the foreseeable future, be limited to electronic observation and analysis.
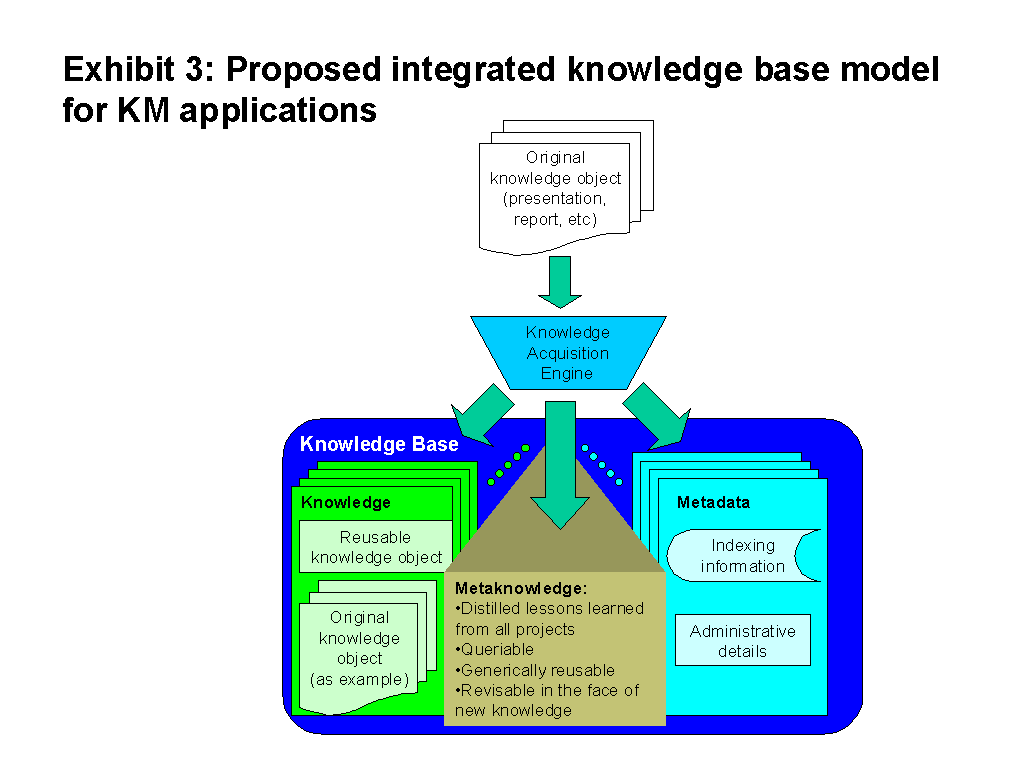
The specific emerging KA technologies that follow are currently nothing more than research projects, and must be viewed as concepts that, through further development, can be applied to KM; they are means to an end, not solutions in themselves. I see these technologies enabling a new knowledge base model that combines the knowledge objects and indexing data found in a traditional database with metaknowledge derived from them, as shown in Exhibit 3. I believe that this can be viewed as one realization of the "synergetic combination of case-specific and general domain knowledge" advocated in (Aamodt, 1995).
My metaknowledge would provide both enhanced searchability of the knowledge base and expert-system-like features. Going beyond the mere recycling of a good document, this metaknowledge would take a step towards providing a coherent picture of all of what the company knows. Of course, it would form only part of the picture; other parts would be filled in by hand—until the arrival of the magic bullet.
Emerging KA technologies can be subdivided into two processes: initial knowledge acquisition, and sustained learning.
Initial acquisition
The main thrust of current KA research lies in constructing knowledge bases for expert systems using a bottom-up approach: given a set of data, the KA system draws conclusions that are represented as rules which can be used to evaluate future input data (Sestito, 1994). This may seem far more straightforward than the KM application of extracting and revising knowledge from generic and unpredictable electronic documents, but I assert that the fundamental concepts apply.
The main difference between expert system KA and knowledge management KA is the form of the input data; expert system knowledge bases are "trained" with rigidly formatted, typically contrived data sets, while KM knowledge bases must extract knowledge from unprepared documents (currently this extraction if performed by humans). The bridge between the two, I believe, lies in Natural Language Processing. Fortunately, NLP is a well-studied field; the ability to decompose natural language documents into their key concepts is highly developed (Brill, 1997). Unfortunately, research activity into how best to use this conceptual document data as input for a KA system is lacking.
The gap from NLP output to KA input is a straightforward problem and will inevitably be bridged; when it is, the next step is to find the representation scheme that best facilitates learning from the knowledge. Current representation schemes fall into two categories: symbolic and sub-symbolic.
Symbolic schemes represent knowledge in ways analogous to traditional data structures. They exclusively employ "supervised" learning; given a series of input examples, they extract the common themes that satisfy given output requirements, and store the themes like a traditional program stores data. Examples include Production rules and decision trees, which are well-suited to procedural knowledge since they lend themselves to test structuring; frames and semantic nets are less concerned with decisions and more concerned with packaging knowledge in an object-oriented manner. In general, symbolic schemes tend to be explicit, rigid, and do not support abstraction well (Sestito, 1994).
Sub-symbolic schemes are exemplified by neural networks, which consist of decision nodes called neurones whose sole purpose is to look at inputs being received over their dendrites and determine whether to send output over their axons. In supervised training, exposure to an input/output training set creates a unique pathway through the neural net, which it will reproduce for similar inputs in the future. However, unlike symbolic schemes, neural nets are capable of unsupervised learning, in which they discover structure in the input data from which they draw conclusions. Also unlike symbolic schemes, neural nets are more adept at dealing with ambiguity; since the input-to-output mapping consists of numerous pathways through the network, slight changes in the input will not affect the final result (Sestito, 1994).
While neural nets are more often associated with classification and connection problems than knowledge management (Raggett, 1992), I think that their strengths—especially their unsupervised learning ability—make them compelling representation schemes for KM knowledge bases. I would not advocate the expense of custom-made neural net hardware for such systems. Rather, I would propose a "virtual neural net" running on traditional hardware. Furthermore, this neural network is only proposed to hold the metaknowledge shown in Exhibit 3; it may not be the most efficient means of storing the other components of the knowledge base, and may have to be combined with a more traditional scheme for these.
Of course, human Knowledge Managers don’t just acquire knowledge from electronic documents; their other sources include observation of and interviews with human experts. Of these, observational KA shows the greatest promise, as current research indicates that it can be implemented transparently.
The PLANDOC system (McKeown, 1995) is a very task-specific observational KA tool, but its operational concepts could theoretically be extended. PLANDOC basically "watches" a telephone network planner interact with the software he uses in his job; when he’s done it intelligently summarizes the job in natural language. Working from raw data, PLANDOC determines which actions were essential and ensures that they are included, but also inserts interesting but non-essential information opportunistically.
With appropriate development, such a system could be refined to observe, say, a consultant writing a report, or creating a presentation, or even composing email that offered insight into the solution of a problem; the output could then be fed to the main KA engine for addition to the knowledge base.
Sustained learning
Once the KM software of the future acquires knowledge, it cannot rest. Like its present-day human counterpart, the future KM system will refine and revise its knowledge through experience as it learns more.
At its simplest level, sustained learning involves the inclusion of new, non-contradictory information. What I call metaknowledge in Exhibit 3 is stored as generalized experience (Aamodt, 1995): given situation X, we know from experience we’ll get result Y. Sustained learning can add similar new rules (called belief update), or amend existing ones (belief revision). Belief update is straightforward; it’s the same as initial acquisition. Belief revision is trickier, as it involves contradictory information that requires the knowledge base to determine whether to revise what it knows (Katsuno, 1991).
Much research has been done attempting to devise a belief revision algorithm. The most promising model appears to be the "theory based" theory of beliefs, in which knowledge is maintained as a collection of theories that represent both the explicit and implicit beliefs it contains (Elio, 1997). Syntax-independence ensures that this model accepts belief updates that are logically equivalent to existing beliefs, regardless of how they are stated. Of the several belief revision models proposed under this model (probabilistic, coherentist and foundationalist), the probabilistic would probably best facilitate KM belief revision. This model assigns probabilities to existing beliefs and evaluates contradictions based on their probability of being true according to the aggregated probabilities of applicable (similar) existing beliefs. This is attractive from a KM perspective since it considers all previously acquired knowledge in deciding the merit of a contradiction, but also considers (through probabilities) the relevance of this knowledge.
The technologies described above come from very disparate sources. In researching them, I found many concepts from AI, cognitive science and library science that could be applied to Knowledge Management; and I was only researching the technology aspect of KM. I think this is a good illustration of the breadth of the field, and good reinforcement of my introductory assertion that KM is in its infancy.
History dictates that the science of KM, like any science, will advance. The name may change, and the progress may not follow the exact paths I have set out for it here, but I think the KM-potential of the technologies discussed here make their assimilation into the field eventually inevitable. I’m confident that when these technologies are refined and combined with future developments—in both technology and other areas of KM—the world will finally have my magic KM bullet.
[1] About a 1000x increase in power and memory every 20 years for the last 40 years.
[2] Trillion Floating Point Operations per Second
[3] It is well beyond the scope of this paper to provide a full treatment of the strong vs. weak AI debate. The interested reader is referred to (Tipler, 1994), (Penrose, 1989), (Kenny, 1972), and (Hofstadter, 1989).
Aamodt, Agnar. "Knowledge acquisition and learning by experience." Machine Learning and Knowledge Acquisition. Edited by Tecuci, Gheorghe and Yves Kodratoff. London: Academic Press Limited, 1995.
Brill, Eric and Raymond J. Mooney. "An Overview of Empirical Natural Language Processing." AI Magazine, Volume 18, Number 4, Winter 1997: 13-24.
Davenport, Thomas H. and Laurence Prusak. Working Knowledge. Boston: Harvard Business School Press, 1998.
Davenport, Thomas H. Knowledge Management at Andersen Consulting (case study). Austin: University of Texas, 1997.
Elio, Renée and Francis Jeffry Pelletier. "Belief Change as Propositional Update." Cognitive Science, Volume 21, Number 4, 1997: 419-460.
Hofstadter, Douglas R. Gödel, Escher, Bach: An Eternal Golden Braid. New York: Random House, Inc., 1989.
Katsuno, H. and Mendelson, A. "Propositional knowledge base revision and minimal change." Artificial Intelligence, Volume 52, 1991: 263-294.
Kenny, Anthony J.P., H. C. Longuet-Higgins, J. R. Lucas, and C. H. Waddington. The Nature of the Mind: Gifford Lectures 1971-1973. Edinburgh: Edinburgh University Press, 1972
McKeown, Kathleen, et al. "Generating Concise Natural Language Summaries." Information Processing and Management, Volume 31, Number 5, 1995: 703-733.
Penrose, Roger. The Emperor’s New Mind: Concerning Computers, Minds and the Laws of Physics. Oxford: Oxford University Press, 1989.
Raggett, Jenny and William Bains. Artificial intelligence from A to Z. London: Chapman & Hall, 1992.
Sestito, Sabrina and Tharam S. Dillon. Automated Knowledge Acquisition. Sydney: Prentice Hall of Australia Pty Ltd, 1994.
Tipler, Frank J. The Physics of Immortality: Modern Cosmology, God and the Resurrection of the Dead. New York: Doubleday, 1994.
{kind=link}
{kind=link}
{kind=link}